Why this was written:
In a couple of linux device
drivers I recently discovered integer overflows leading to overwriting
of memory allocated with kmalloc(). I was curious if it was
possible to reliably exploit an overflow of this type, possibly similar
to malloc() exploits. I Googled, posted on newsgroups, and
posted on Bugtraq expecting that someone could answer this for me. I
recieved no answers; so either nobody else has researched this before(unlikely),
or they didn't feel like sharing. Either way, I wanted to find out
for myself and share what I learned. In order to answer this question,
it was first necessary to learn how memory allocation is handled in the
kernel.
Notes:
Understanding this requires
a minimal understanding of the linux kernel. Sometimes I may use
the names of functions that are commonly known. If you don't know
what they are, a quick Google or grep through the include directory should
find them for you. All of the cache related functions I mention can
be found in the file /usr/src/linux/mm/slab.c. Some of the numbers
I give are only applicable on IA-32 architectures. I've tried to
bold function names and data types, and italicize
defined constants, but odds are I missed a few. In some of the code
shown I have cut out debugging code. I have ignored some of the SMP
code because I don't have an SMP system; yea I'm a slacker. Also,
I'm a n00b; you've been warned. Still going to read this?
Overview:
Any operating system kernel
needs a way to manage physical memory. Device drivers, and various
other parts of the kernel need to be able to allocate chunks of memory to
store data. This memory comes from system RAM, and when one speaks
of system RAM, it is always addressed in PAGE_SIZE chunks. On
some architectures this corresponds to 4096 bytes, but this size varies:
for example Alphas use 8192 bytes for a page. However, when some driver
or other kernel function needs to dynamically allocate memory, it does not
always need an entire page(s). Thus, there is a need for some entity
that can manage system RAM and dole it out to those who request it in varying
sized chunks. Such an allocator should carefully balance two goals:
speed, and minimizing the amount of fragmented, unusable memory leftover
in chunks allocated. The latter being especially important, since
any fragmented memory is wasted system RAM that will not be reclaimed as
long as the memory chunk it belongs to is in use. This job is performed
by the kmalloc() function, and its counterpart kfree().
Kmalloc doesn't do much:
I lied a bit when I said that
kmalloc() had the job of managing memory. In fact, it is
just an interface to the REAL memory manager, the kmem cache allocator.
So, in order to understand kmalloc(), what is really needed
is to first understand the cache allocation scheme. That will be the
focus of this discussion. After understanding that, you will see that
kmalloc() is merely just a user of the cache allocators services.
Cache overview:
The idea behind a cache allocator
is quite simple: divide up memory into pools of objects, where each pool
contains objects of the same size, and different pools contain objects of
other sizes. Then, when someone requests a block of memory of a given
size, find the first pool large enough to hold a block that size and hand
it over. And that's about all there is to it. Underneath this
frame is a bit more complexity. Some things to consider: how large
should each pool be? If we run out of objects in one pool, how do
we create more? How do we track which objects in the pool are
free or in use? How many pools should we have, and how large
should the gaps be between pool sizes? The question in italics is
one that is especially important to us, because as you may guess, taking
care of free/allocated memory involves some sort of control structures.
If these control structures lie in a place where we can overwrite,
exploitation may be possible. The mixing of control and data channels
is at the root (well bad code is the real root) of most exploitation techniques.
As said, memory is divided up into pools of objects. One of these pools is referred to as a cache, and there are many of these caches in the kernel. The key data structure behind all of this is the kmem_cache_t data type. It is used to hold all sorts of information about the cache it refers to, such as the size of each object and the number of objects found in each pool. There exists one of these data types for each different cache in the system. Drivers and the like are able to create their own caches of a size they choose. If a driver does this, it will create its cache by calling the kmem_cache_create() function. This function creates a cache of objects whose size is provided by the caller, and then it inserts this cache into the global list of created caches called the cache_cache. The cache_cache is itself a static kmem_cache_t object, and it is used to hold all of the system wide caches. Therefore the size of objects in its pool is sizeof(kmem_cache_t). You can can view all of the caches in the system by looking at the file /proc/slabinfo. In addition to this global 'cache of caches', we also have the general caches. The general caches are an array of caches, each sized a power of 2 greater than the last one. On IA-32 these sizes start at 32, and go up until 131,072 by multiples of 2. For each size, there are two caches, a cache for normal memory, and a cache for DMA capable memory. On IA-32, DMA memory must be at an address that is addressable with 16 bits. This is how kmalloc() works. When kmalloc() is called, all it does is search through the general caches until it finds a suitably sized cache, and then calls __kmem_cache_alloc() to grab an object from that cache and returns it to the caller. Similarly, kfree() just returns the object to its cache by calling __kmem_cache_free().
As said, memory is divided up into pools of objects. One of these pools is referred to as a cache, and there are many of these caches in the kernel. The key data structure behind all of this is the kmem_cache_t data type. It is used to hold all sorts of information about the cache it refers to, such as the size of each object and the number of objects found in each pool. There exists one of these data types for each different cache in the system. Drivers and the like are able to create their own caches of a size they choose. If a driver does this, it will create its cache by calling the kmem_cache_create() function. This function creates a cache of objects whose size is provided by the caller, and then it inserts this cache into the global list of created caches called the cache_cache. The cache_cache is itself a static kmem_cache_t object, and it is used to hold all of the system wide caches. Therefore the size of objects in its pool is sizeof(kmem_cache_t). You can can view all of the caches in the system by looking at the file /proc/slabinfo. In addition to this global 'cache of caches', we also have the general caches. The general caches are an array of caches, each sized a power of 2 greater than the last one. On IA-32 these sizes start at 32, and go up until 131,072 by multiples of 2. For each size, there are two caches, a cache for normal memory, and a cache for DMA capable memory. On IA-32, DMA memory must be at an address that is addressable with 16 bits. This is how kmalloc() works. When kmalloc() is called, all it does is search through the general caches until it finds a suitably sized cache, and then calls __kmem_cache_alloc() to grab an object from that cache and returns it to the caller. Similarly, kfree() just returns the object to its cache by calling __kmem_cache_free().
Caches and slabs:
The key data structure behind caches is the kmem_cache_t type. It has numerous members, here are some the most important ones:struct list_head slabs_full;
struct list_head slabs_partial;
struct list_head slabs_free;
The lists of slabs for this cache. These are explained below.
unsigned int objsize;
The size of each object in this cache.
unsigned int flags;
Flags for this cache. Determine certain optimizations, and where the object tracking information is stored.
unsigned int num;
The number of objects stored on each slab.
spinlock_t spinlock;
To protect the structure from concurrent access by CPUS.
unsigned int gfporder;
The base 2 logarithm (2^n) number of pages to allocate for each slab.
unsigned int gfpflags;
The flags passed to get_free_pages() when allocating memory, used for specifying DMA memory is needed,
or that the caller does not want to be put to sleep if there is no memory available.
char name[CACHE_NAMELEN];
The name of the cache, will be output in /proc/slabinfo along with usage statistics.
struct list_head next;
When this cache is user created and belongs to the global cache_cache list, this sews it into the list.
void (*ctor)(void *, kmem_cache_t *, unsigned long);
void (*dtor)(void *, kmem_cache_t *, unsigned long);
The constructor/destructor can be passed by the creator of the cache, and will run whenever a slab is created/freed.
There are some other fields used to keep statistics, as well as some SMP specific fields, and a couple we will see later.
In order to organize the objects in each cache, the kernel relies on slabs. A slab hosts a number of objects, and possibly the control information needed to manage the objects stored in the slab. Each cache consists of multiple slabs, and each slab consists of multiple objects. A slab itself is merely a number of pages of physical memory allocated by the get_free_pages() function. In order to organize all of its slabs, a cache manages three separate doubly linked lists of slabs, using the standard kernel list implementation. You saw the heads of these three lists in the above variables. One list is for slabs that have no objects on them, the free list, another list is for slabs that are partially full of objects, the partial list, and the third list is for slabs that are completely full of objects, the full list. Each slab, represented by the slab_t type, contains a list pointer used to sew all the slabs in a list together. That is, each slab allocated for a cache will reside in one of the three lists. There can be many slabs in a list, and they are sewn together via pointers embedded in each slab, with the head of the list in the kmem_cache_t object. Here is a visualization of this:
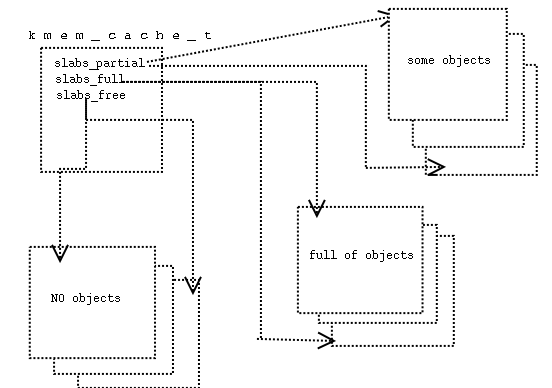
The large boxes are slabs. Each slab in a list also contains forward and backward pointers to the corresponding slabs in the list, these are not shown.
Slab and object management:
So, as we can see the slab
is where all of the objects are actually stored. In addition to storing
objects, the slab also is responsible for managing all of the objects that
it contains. The control information consists of two structures, slab_t
and kmem_bufctl_t. They are shown here:
typedef struct slab_s {
struct list_head list; /* linkage into free/full/partial lists */
unsigned long colouroff; /* offset in bytes of objects into first page of slab */
void *s_mem; /* pointer to where the objects start */
unsigned int inuse; /* num of objs allocated in the slab */
kmem_bufctl_t free; /*index of the next free object */
} slab_t;
typedef struct slab_s {
struct list_head list; /* linkage into free/full/partial lists */
unsigned long colouroff; /* offset in bytes of objects into first page of slab */
void *s_mem; /* pointer to where the objects start */
unsigned int inuse; /* num of objs allocated in the slab */
kmem_bufctl_t free; /*index of the next free object */
} slab_t;
typedef unsigned int kmem_bufctl_t;
/* tracks indexes of free objects, starting at base slab_t->s_mem */
Allocating objects:
When objects are allocated,
the list of slabs is traversed in the following order: first we search
the partial slabs list and grab the first one, if this list is empty, we
then search the free slabs list and grab the first one, and finally, if this
list is also empty then we allocate a new slab and add it to the free list,
using this slab for our object.
The kmem_buf_ctl_t type is used to track which objects in the slab are free. There is an array of these, the size of this array is equal to the number of objects that is stored in this slab. This array is store directly after the slab_t structure for each slab. Each member in this array originally starts out as equal to its index + 1, so index 0 contains 1, index 1 contains 2, and so on. The value stored in each index represents an offset into the area pointed to by s_mem where a corresponding object lies. When an object is needed from the slab, this code is run:
The kmem_buf_ctl_t type is used to track which objects in the slab are free. There is an array of these, the size of this array is equal to the number of objects that is stored in this slab. This array is store directly after the slab_t structure for each slab. Each member in this array originally starts out as equal to its index + 1, so index 0 contains 1, index 1 contains 2, and so on. The value stored in each index represents an offset into the area pointed to by s_mem where a corresponding object lies. When an object is needed from the slab, this code is run:
#define slab_bufctl(slabp) ((kmem_bufctl_t *)(((slab_t*)slabp)+1))
void *objp; /* the object that will be returned to caller */
slab_t *slabp = current_slab;
kmem_cache_t *cachep = current_cache;
objp = slabp->s_mem + slabp->free*cachep->objsize;
slabp->free=slab_bufctl(slabp)[slabp->free];
The slab->free member is
initially allocated to 0, so on the first object allocation u can see that
it will return the memory pointed to by slabp->s_mem, which is the first
object in the slab. Then slabp->free is updated with the value
stored at index slabp->free in the bufctl array. Since the bufctl
array is stored directly after the slab_t structure, the slab_bufctl macro
just returns the start of that array.
Freeing objects:
Now at first this scheme may
not make much sense, but once you see how objects are returned to the slab
it is actually quite clever and makes perfect sense. Here is how
an object is returned:
void *objp = pointer to current object being freed;
slab_t *slabp = slab object belongs to;
kmem_cache_t *cachep = current_cache;
/* get the index of this object offset from s_mem */
unsigned int objnr = (objp-slabp->s_mem)/cachep->objsize;
slab_bufctl(slabp)[objnr] = slabp->free;
slabp->free = objnr;
Since objp points to the current
object being freed, and slabp->s_mem points to the base address where
objects begin in this slab, we subtract and divide by the cache size to
get the index of this object. Here the index into the bufctl array
of this object is updated with the previous index that would of been used
for a new object, and the next index to be used is set to the object that
was just freed. This technique allows the array of bufctls to be traversed
sequentially: the object returned upon requesting a new object will
always be the object that is at the lowest address. By saving our
place each time we can move from the start of the bufctl list to the end
without any other state. Once we get to the end of the bufctl array,
we know the slab is full.
Managing slabs lists:
The last index of kmem_bufctl_t
array contains a value of BUFCTL_END. When the slabp->free
member gets to this value, we now know that the slab is full, illustrated
by this code that follows the allocation code shown above:
/* is this slab full? add it to the full list if so */
if (unlikely(slabp->free == BUFCTL_END)) {
list_del(&slabp->list);
list_add(&slabp->list, &cachep->slabs_full);
}
We check to see if this allocation
makes the slab full, and if so, we remove the slab from the partial or
empty list, and add it to the full list.
In addition to the above, we also need to know when a slab moves from being full to partially full, or partially full to free, and lastly from free to partially full. The first two cases are handled with the following code, that executes shortly after above code when freeing an object:
In addition to the above, we also need to know when a slab moves from being full to partially full, or partially full to free, and lastly from free to partially full. The first two cases are handled with the following code, that executes shortly after above code when freeing an object:
/* just freed an object, so fixup slab chains. is slab now empty? is slab not full anymore? */
int inuse = slabp->inuse;
if (unlikely(!--slabp->inuse)) {
/* Was partial or full, now empty. */
list_del(&slabp->list);
list_add(&slabp->list, &cachep->slabs_free);
} else if (unlikely(inuse == cachep->num)) {
/* Was full. */
list_del(&slabp->list);
list_add(&slabp->list, &cachep->slabs_partial);
}
The inuse member holds the
number of objects currently being used in the slab. When this hits
0 we remove it from the list it was on and add it to the free list. The
cachep->num member holds the maximum number of objects a slab can hold,
so if the slab was previously full, since we are removing an object we
add it to the partially full list.
The third case, slabs moving from free to partially full is handled whenever we add an object to a free slab. It is just a couple lines of code not worth showing. It is found in the kmem_cache_alloc_one() macro if you're interested.
The third case, slabs moving from free to partially full is handled whenever we add an object to a free slab. It is just a couple lines of code not worth showing. It is found in the kmem_cache_alloc_one() macro if you're interested.
So where is the slab control info stored:
Finally, what we've been waiting
for... Well, it is one of two places, and unfortunately neither of
them is very friendly for exploitation. If a slab contains objects
that are >= (PAGE_SIZE>>3), 512 bytes on IA-32, or if the caller
to kmem_cache_create() specifies the CFLGS_OFF_SLAB flag
(which the kmalloc() caches DO NOT), then the slab control info
will be stored OFF of the slab, in a cache of its own. However, if
neither of those situations occur, then the slab control info will be stored
BEFORE all of the objects in the slab. The following illustrates that:


So, in the latter case the
control info is stored off slab, and we have no angle at all. This
occurs with any kmalloc()'d memory that is greater than or equal
to 512 bytes. In the first case, the slab control is stored BEFORE
the objects, and in addition to this, we will never find two slabs allocated
one after another, unless by sheer luck from a call to get_free_pages()
when allocating the slabs. So, unless we have an underflow of a buffer,
exploitation does not seem to be possible. Even in the event of an
underflow, we would have no idea where our object is located in the slab.
Ignoring this though, if we can keep traversing up the slab until we hit
the slab_t structure then some sort of exploitation is possible. We
can overwrite the list pointers, and point them to a fake slab we create
in the overflowed area. Then, when this slab is worked on by one of
the list functions we can write nearly arbitrary values to arbitrary memory,
similar to malloc style exploitation. A problem though is that we
are destroying the list this slab is chained on, and unless we can work
some magic to repair this damage a system crash would follow soon after
exploitation. I didn't pursue this angle much further, because the
circumstances needed to bring it about are not very likely. But given
the right situation it would be possible, but extremely difficult to exploit.
The other unlikely and nearly impossible to predict chance of exploitation
lies in the fact that off-slab control structures are kept in one of the
general caches. Through some simple math we can accurately predict
which cache contains the control info for all memory allocations greater
than or equal to 512 bytes. This control info will be stored in the
slab along with other objects, so if we happened to have an object located
at a lower memory address on the same slab as one of these control blocks,
and if that buffer can be overflowed, then we can manipulate the slab_t
data. However, you would have no idea if this situation was actually
occurring without tracing every single call to kmalloc() from system
startup, so I don't think that's a viable strategy.
If all you wanted to know was if exploitation was possible, then you can stop reading here. If you want a in depth explanation of how the rest of the cache allocation scheme works, then continue on. The remainder of this paper will explain all of the functions found in mm/slab.c, in order to understand cache managment from start to finish. What follows is some short descriptions of functions, and source code with my inlined comments.
Note: If you aren't going to read the rest, you may be interested in viewing this kmalloc performance table
If all you wanted to know was if exploitation was possible, then you can stop reading here. If you want a in depth explanation of how the rest of the cache allocation scheme works, then continue on. The remainder of this paper will explain all of the functions found in mm/slab.c, in order to understand cache managment from start to finish. What follows is some short descriptions of functions, and source code with my inlined comments.
Note: If you aren't going to read the rest, you may be interested in viewing this kmalloc performance table
Cache Data Structures:
There are three important global
structures involved with caches. One is the cache_cache, its
semaphore that protects concurrent access to it, and the other is the general
cache used by kmalloc(). Here they are with some inlined comments:
/* an array of these structures represents the memory available for kmalloc() */
typedef struct cache_sizes {
size_t cs_size; /* the size of the cache objects */
kmem_cache_t *cs_cachep; /* used for regular kmalloc'd memory */
kmem_cache_t *cs_dmacachep; /* used for DMA kmalloc'd memory */
} cache_sizes_t;
/* each of these has a cache for DMA and regular memory */
static cache_sizes_t cache_sizes[] = {
#if PAGE_SIZE == 4096
{ 32, NULL, NULL},
#endif
{ 64, NULL, NULL},
{ 128, NULL, NULL},
{ 256, NULL, NULL},
{ 512, NULL, NULL},
{ 1024, NULL, NULL},
{ 2048, NULL, NULL},
{ 4096, NULL, NULL},
{ 8192, NULL, NULL},
{ 16384, NULL, NULL},
{ 32768, NULL, NULL},
{ 65536, NULL, NULL},
{131072, NULL, NULL},
{ 0, NULL, NULL}
};
/* internal cache of cache description objs
* this holds all of the caches themselves through the next list pointer not shown here */
static kmem_cache_t cache_cache = {
slabs_full: LIST_HEAD_INIT(cache_cache.slabs_full),
slabs_partial: LIST_HEAD_INIT(cache_cache.slabs_partial),
slabs_free: LIST_HEAD_INIT(cache_cache.slabs_free),
objsize: sizeof(kmem_cache_t),
flags: SLAB_NO_REAP,
spinlock: SPIN_LOCK_UNLOCKED,
colour_off: L1_CACHE_BYTES, /* 32 */
name: "kmem_cache",
};
/* Guard access to the cache-chain. */
static struct semaphore cache_chain_sem;
Startup, Cache Initialization
On system startup, two things
need to be done. The cache_cache needs to be initialized by
determining the number of objects per slab, and each of the caches in the
array of general caches need to be created. The first task is accomplished
in the kmem_cache_init() function, and the second via the kmem_cache_sizes_init().
Setting up the number of objects that will fit in a slab is accomplished
with the kmem_cache_estimate() function, shown below with comments.
The general cache initialization just calls kmem_cache_create()
to create each one of the different sized general caches and is not worth
showing.
/* Cal the num objs, wastage, and bytes left over for a given slab size.
* @param gfporder - slab size in 2^n form
* @param size - the size of a single cache object
* @flags - flags for allocation
* @left_ofter - how many bytes will be wasted in slab
* @num - how many objects will fit in the slab */
static void kmem_cache_estimate (unsigned long gfporder, size_t size,
int flags, size_t *left_over, unsigned int *num)
{
int i;
size_t wastage = PAGE_SIZE<<gfporder; /* total size being asked for */
size_t extra = 0;
size_t base = 0;
/* if we're not storing control info off the slab, add size of control
* structs to the size */
if (!(flags & CFLGS_OFF_SLAB)) {
base = sizeof(slab_t);
extra = sizeof(kmem_bufctl_t);
}
/* calc the number of objects that will fit inside the slab, including the
* base slab_t and a kmem_bufclt_t for each as well */
i = 0;
while (i*size + L1_CACHE_ALIGN(base+i*extra) <= wastage)
i++;
if (i > 0)
i--;
/* this limit is absurdly huge... 0xfffffffe */
if (i > SLAB_LIMIT)
i = SLAB_LIMIT;
/* return number objects that fit, and total space wasted */
*num = i;
wastage -= i*size;
wastage -= L1_CACHE_ALIGN(base+i*extra);
*left_over = wastage;
}
This function is used to determine
how many objects will fit on slabs of a given order, and how much space
will be wasted at the end of the slab. The caller passes in the gfporder
parameter, the object size, and cache flags. The pointers it passes
are filled in by the function. When this is called by kmem_cache_init()
it is only to determine how many objects fit in each slab. However,
we'll see that when this function is called later on by the kmem_cache_create()
function it is called in a loop that tries to minimize wastage.
Getting/Freeing Physical Memory:
As mentioned before, internally
the cache allocator relies on the get_free_pages() function to allocate
pages of memory for its slabs. Each slab consists of some 2^n number
of physical pages. It is that simple, and not worth showing. The
two functions kmem_getpages() and kmem_freepages() are used
to allocate pages for a new slab, or free pages for a slab being destroyed.
Slab Creation and Destruction:
After a slab has been created,
it must be initialized. Two functions do this, kmem_cache_slabmgmt()
and kmem_cache_init_objs(). The first one aligns the slab_t
pointer on a proper boundary if the control is on-slab, or if it is off-slab
it allocates an area for it using kmem_cache_alloc(). This
area will be one of the general areas used for kmalloc(). It
also initializes the s_mem member to point to the base where objects start.
The second function has two roles: calling the constructor for each
object on the slab if the user provided one at cache creation time, and
also setting the kmem_bufctl_t array. This second part merely
initializes each index as described above, to its index + 1, and the final
index to BUFCTL_END.
Destroying a slab is equally simple. If a destructor was specified, then we call it for each object in the slab. Then we free the pages used by the slab with kmem_freepages(). If the slab control data was stored off-slab, we free it from its cache.
Destroying a slab is equally simple. If a destructor was specified, then we call it for each object in the slab. Then we free the pages used by the slab with kmem_freepages(). If the slab control data was stored off-slab, we free it from its cache.
Cache Creation and Destruction:
Now that we have a good understanding
of the lower levels of cache management, we can discuss the upper layers.
There are two functions responsible for creating/removing caches from
the kernel. kmem_cache_create() and kmem_cache_destroy(),
i'll leave it up to you to decide which does what. Rather than describe
what they do, I'll show the code for each with my comments along with developers.
Also, note that when the cache is first created it has NO slabs in it,
upon the first allocation of an object a slab will be created by the kmem_cache_grow()
function we'll see later.
/**
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.
* @size: The size of objects to be created in this cache.
* @offset: The offset to use within the page.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
* @dtor: A destructor for the objects.
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a int, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache
* and the @dtor is run before the pages are handed back.
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_NO_REAP - Don't automatically reap this cache when we're under
* memory pressure.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
kmem_cache_t *
kmem_cache_create (const char *name, size_t size, size_t offset,
unsigned long flags, void (*ctor)(void*, kmem_cache_t *, unsigned long),
void (*dtor)(void*, kmem_cache_t *, unsigned long))
{
const char *func_nm = KERN_ERR "kmem_create: ";
size_t left_over, align, slab_size;
kmem_cache_t *cachep = NULL;
/*
* Sanity checks... these are all serious usage bugs.
*/
if ((!name) ||
((strlen(name) >= CACHE_NAMELEN - 1)) ||
in_interrupt() ||
(size < BYTES_PER_WORD) ||
(size > (1<<MAX_OBJ_ORDER)*PAGE_SIZE) ||
(dtor && !ctor) ||
(offset < 0 || offset > size))
BUG();
/*
* Always checks flags, a caller might be expecting debug
* support which isn't available. we check to make sure the caller hasn't specified
* any flags that are not part of the allowed mask.
*/
BUG_ON(flags & ~CREATE_MASK);
/* Get cache's description obj. each cache that the user creates is part of the master cache_cache. this cache
* holds kmem_cache_t objects */
cachep = (kmem_cache_t *) kmem_cache_alloc(&cache_cache, SLAB_KERNEL);
if (!cachep)
goto opps;
memset(cachep, 0, sizeof(kmem_cache_t));
/* Check that size is in terms of words. This is needed to avoid
* unaligned accesses for some archs when redzoning is used, and makes
* sure any on-slab bufctl's are also correctly aligned.
*/
if (size & (BYTES_PER_WORD-1)) {
size += (BYTES_PER_WORD-1);
size &= ~(BYTES_PER_WORD-1);
printk("%sForcing size word alignment - %s\n", func_nm, name);
}
/* how should it be aligned, sizeof(void *) or L1CS */
align = BYTES_PER_WORD;
if (flags & SLAB_HWCACHE_ALIGN)
align = L1_CACHE_BYTES;
/* Determine if the slab management is 'on' or 'off' slab. if size is large,
* place management in it's own cache. this means we can't exploit here */
if (size >= (PAGE_SIZE>>3))
flags |= CFLGS_OFF_SLAB;
if (flags & SLAB_HWCACHE_ALIGN) {
/* Need to adjust size so that objs are cache aligned. */
/* Small obj size, can get at least two per cache line. */
/* FIXME: only power of 2 supported, was better */
while (size < align/2)
align /= 2;
size = (size+align-1)&(~(align-1));
}
/* Cal size (in pages) of slabs, and the num of objs per slab.
* This could be made much more intelligent. For now, try to avoid
* using high page-orders for slabs. When the gfp() funcs are more
* friendly towards high-order requests, this should be changed.
* order starts out at 0 and increments.
* this loop is where we really use the estimate function that was shown above. we go around the loop trying to
* find an order of pages that doesn't waste a lot of slab space. each time around the loop we increment the order.
* remember that order is the base 2 log(2^n) of how many pages for the slab. when we find an acceptable amount
* of space left over, or when we max out at order of 5, we break out of the loop. the estimate function has filled
* in the the number of objects per slab for us.
*/
do {
unsigned int break_flag = 0;
cal_wastage:
kmem_cache_estimate(cachep->gfporder, size, flags,
&left_over, &cachep->num);
if (break_flag)
break;
if (cachep->gfporder >= MAX_GFP_ORDER)/* order == 5, 32 pages */
break;
if (!cachep->num) /* we couldnt fit any objects on slab */
goto next;
/* obey limit on max # objects for off_slab caches */
if (flags & CFLGS_OFF_SLAB && cachep->num > offslab_limit) {
/* Oops, this num of objs will cause problems. */
cachep->gfporder--;
break_flag++;
goto cal_wastage;
}
/*
* Large num of objs is good, but v. large slabs are currently
* bad for the gfp()s... this is only 2 pages per slab
*/
if (cachep->gfporder >= slab_break_gfp_order)
/* WTF?? doesn't this seem huge? guess it's best u can do.. */
if ((left_over*8) <= (PAGE_SIZE<<cachep->gfporder))
break; /* Acceptable internal fragmentation. */
next:
cachep->gfporder++;
} while (1);
/* couldn't fit any objects into this size slab; they must be huge */
if (!cachep->num) {
printk("kmem_cache_create: couldn't create cache %s.\n", name);
kmem_cache_free(&cache_cache, cachep);
cachep = NULL;
goto opps;
}
/* total size of slab control objects aligned for L1, includes:
* bufctl_t for each object, and slab_t struct */
slab_size = L1_CACHE_ALIGN(cachep->num*sizeof(kmem_bufctl_t)+sizeof(slab_t));
/*
* If the slab has been placed off-slab, and we have enough space then
* move it on-slab. This is at the expense of any extra colouring.
* colouring involves offsetting the slab_t structure into the slab area to maximize cache alignment
*/
if (flags & CFLGS_OFF_SLAB && left_over >= slab_size) {
flags &= ~CFLGS_OFF_SLAB;
left_over -= slab_size;
}
/* Offset must be a multiple of the alignment. */
offset += (align-1);
offset &= ~(align-1);
if (!offset)
offset = L1_CACHE_BYTES;
cachep->colour_off = offset;
cachep->colour = left_over/offset;
/* init remaining fields */
/* for single page slabs we do some optimizing for lookup, this isn't
* currently in use in this code */
if (!cachep->gfporder && !(flags & CFLGS_OFF_SLAB))
flags |= CFLGS_OPTIMIZE;
cachep->flags = flags;
cachep->gfpflags = 0;
if (flags & SLAB_CACHE_DMA)
cachep->gfpflags |= GFP_DMA;
spin_lock_init(&cachep->spinlock);
cachep->objsize = size;
INIT_LIST_HEAD(&cachep->slabs_full);
INIT_LIST_HEAD(&cachep->slabs_partial);
INIT_LIST_HEAD(&cachep->slabs_free);
/* off slab control structs use regular cache bins. the find_general function just picks out
* one of the general caches used by kmalloc() that is large enough to hold our info */
if (flags & CFLGS_OFF_SLAB)
cachep->slabp_cache = kmem_find_general_cachep(slab_size,0);
cachep->ctor = ctor;
cachep->dtor = dtor;
/* Copy name over so we don't have problems with unloaded modules */
strcpy(cachep->name, name);
#ifdef CONFIG_SMP
if (g_cpucache_up)
enable_cpucache(cachep);
#endif
/* make sure this cache doesn't already exist in master cache, if it does == trouble */
down(&cache_chain_sem);
{
struct list_head *p;
list_for_each(p, &cache_chain) {
kmem_cache_t *pc = list_entry(p, kmem_cache_t, next);
/* The name field is constant - no lock needed. */
if (!strcmp(pc->name, name))
BUG();
}
}
/* add our cache into master list */
list_add(&cachep->next, &cache_chain);
up(&cache_chain_sem);
opps:
return cachep;
}
/**
* kmem_cache_destroy - delete a cache
* @cachep: the cache to destroy
*
* Remove a kmem_cache_t object from the slab cache.
* Returns 0 on success.
*
* It is expected this function will be called by a module when it is
* unloaded. This will remove the cache completely, and avoid a duplicate
* cache being allocated each time a module is loaded and unloaded, if the
* module doesn't have persistent in-kernel storage across loads and unloads.
*
* The caller must guarantee that noone will allocate memory from the cache
* during the kmem_cache_destroy().
*/
int kmem_cache_destroy (kmem_cache_t * cachep)
{
if (!cachep || in_interrupt() || cachep->growing)
BUG();
/* Find the cache in the chain of caches, and remove it from the list w/ semaphore held. */
down(&cache_chain_sem);
/* clock_searchp is used in a different function that frees up extra cache memory.
* it points to the last cache that was freed up. so if was pointing to
* the cache being destroyed, we just move it on to the next cache in chain. */
if (clock_searchp == cachep)
clock_searchp = list_entry(cachep->next.next,
kmem_cache_t, next);
list_del(&cachep->next);
up(&cache_chain_sem);
/* if there are still some slabs left in cache then add cache back to list
* and return to caller. the shrink function as we'll see goes through the free slab list
* and destroys all of the slabs. it returns non-zero if there are any slabs left in either the
* full or partial list. in that case, that means the cache is still in use and we can't destroy it */
if (__kmem_cache_shrink(cachep)) {
printk(KERN_ERR "kmem_cache_destroy: Can't free all objects %p\n",
cachep);
down(&cache_chain_sem);
list_add(&cachep->next,&cache_chain);
up(&cache_chain_sem);
return 1;
}
#ifdef CONFIG_SMP
{
int i;
for (i = 0; i < NR_CPUS; i++)
kfree(cachep->cpudata[i]);
}
#endif
/* remove this cache from the master cache */
kmem_cache_free(&cache_cache, cachep);
return 0;
}
Cache Allocation and Deallocation:
Once a cache is created we
can allocate and free objects from it. This is handled by a couple
of wrapper functions, kmem_cache_alloc() and kmem_cache_free(),
and a number of functions they call internally. We've already seen
part of the code that runs above, and after you read the rest of this document
it will be simple for you to look at these functions yourself. To
give a brief overview:
Allocation:
The kmem_cache_alloc_one()
macro is what gets called inside __kmem_cache_alloc() which is called
by kmem_cache_alloc(). Inside the macro, the following takes
place: we see if there is a partial list, if not then we see if there is
a free list, if not then we create a new slab with the kmem_cache_grow()
function we'll look at next. After this happens, we get the object
with the kmem_cache_alloc_one_tail() function. We already
saw all of the code for this function before when discussing allocating
objects.
Freeing:
After disabling local interrupts,
__kmem_cache_free() is called. On UNP, it then calls kmem_cache_free_one().
We looked at nearly all of the code for this function when discussing
freeing objects. The one part we didn't see yet will be clear after
reading the rest of this paper. So, after doing so you can go back
and look at the rest.
Important Note: How do we determine what slab an object belongs on?
You may have been wondering
this already, and here is how it happens. Recall that a slab is merely
a chunk of contiguous pages. Every page in the system is represented
by a struct page. This structure has a number of fields in,
such as a reference count and a number of flags that determine what the
page is being used for and other things. One of the members in this
structure is a struct list_head type, and it can be used by whomever
owns the page for whatever they need it for. If you are not familiar
with the kernel list implementation, there is plenty of documentation on
it, and the file include/linux/list.h is nearly self explanatory. Here
is the struct list_head type:
struct list_head {
struct list_head *next, *prev;
};
It gets embedded into any structure
that is part of a list. However, in this case we don't use it for
a list. What the slab creation code does is use those two pointers
to store pointers to the kmem_cache_t and the slab_t that
this slab belongs to. It does so using these macros:
/* Macros for storing/retrieving the cachep and or slab from the
* global 'mem_map'. These are used to find the slab an obj belongs to.
* With kfree(), these are used to find the cache which an obj belongs to.
* all take a struct page * as an argument, and a pointer to a cache_t or a
* pointer to a slab_t
*/
#define SET_PAGE_CACHE(pg,x) ((pg)->list.next = (struct list_head *)(x))
#define GET_PAGE_CACHE(pg) ((kmem_cache_t *)(pg)->list.next)
#define SET_PAGE_SLAB(pg,x) ((pg)->list.prev = (struct list_head *)(x))
#define GET_PAGE_SLAB(pg) ((slab_t *)(pg)->list.prev)
These macros are used in functions
we see next. For EVERY page in the slab, this information gets stored.
Then, when we have a pointer to an object we can get a pointer to
its associated struct page using the virt_to_page() function,
which takes a kernel virtual address and returns a pointer to its corresponding
page structure.
Cache Growing and Shrinking:
When the cache is first created,
it has no slabs in it. When a cache has filled up all of its free
and partial slabs, it has no room left for more objects. When either
of these events occur the cache needs to allocate more slabs. This
is handled by kmem_cache_grow(). When the cache is being destroyed,
we need to destroy all of the free slabs. When this occurs the kmem_cache_shrink()
function is called. The grow function adds a slab to the caches free
list. The shrink function removes all slabs from the free list, and
disposes of their memory. Here are both of those functions with comments.
/*
* Grow (by 1) the number of slabs within a cache. This is called by
* kmem_cache_alloc() when there are no active objs left in a cache.
* @param cachep - the cache to grow
* @param flags - slab flags
* @return 1 success, 0 fail - gotta love those consistent return vals
*/
static int kmem_cache_grow (kmem_cache_t * cachep, int flags)
{
slab_t *slabp;
struct page *page;
void *objp;
size_t offset;
unsigned int i, local_flags;
unsigned long ctor_flags;
unsigned long save_flags;
/* Be lazy and only check for valid flags here,
* keeping it out of the critical path in kmem_cache_alloc().
*/
if (flags & ~(SLAB_DMA|SLAB_LEVEL_MASK|SLAB_NO_GROW))
BUG();
/* some caches are not allowed to grow, this checks for that */
if (flags & SLAB_NO_GROW)
return 0;
/*
* The test for missing atomic flag is performed here, rather than
* the more obvious place, simply to reduce the critical path length
* in kmem_cache_alloc(). If a caller is seriously mis-behaving they
* will eventually be caught here (where it matters).
* if you're in an interrupt state, you cannot sleep. by passing the SLAB_ATOMIC flag
* you are saying "don't put me to sleep". so if this isn't provided and we're in interrupt, BUG
*/
if (in_interrupt() && (flags & SLAB_LEVEL_MASK) != SLAB_ATOMIC)
BUG();
/* remember that cache creators can pass a contstructor and destructor that will be called
* at slab creation/deletion. These functions get passed a mask of flags, some people use the
* same function for constr/destr, so we pass them a flag letting them know it's constr. we also
* pass them the atomic flag if necessary, so they know not to sleep
*/
ctor_flags = SLAB_CTOR_CONSTRUCTOR;
local_flags = (flags & SLAB_LEVEL_MASK);
if (local_flags == SLAB_ATOMIC)
/*
* Not allowed to sleep. Need to tell a constructor about
* this - it might need to know...
*/
ctor_flags |= SLAB_CTOR_ATOMIC;
/* About to mess with non-constant members - lock. */
spin_lock_irqsave(&cachep->spinlock, save_flags);
/* Get colour for the slab, and cal the next value. this is used to align the slab_t.
* i'd be lying if i said i knew exactly what it means
*/
offset = cachep->colour_next;
cachep->colour_next++;
if (cachep->colour_next >= cachep->colour)
cachep->colour_next = 0;
offset *= cachep->colour_off;
/* let others know this cache has recently grown, we'll see this later in the 'reaper' code */
cachep->dflags |= DFLGS_GROWN;
/* lock the slab from being reaped or shrunk. we set the growing flag, and other functions test for
* it to make sure that we dont ever try to shrink or destroy a cache in the midst of growing */
cachep->growing++;
spin_unlock_irqrestore(&cachep->spinlock, save_flags);
/* A series of memory allocations for a new slab.
* Neither the cache-chain semaphore, or cache-lock, are
* held, but the incrementing c_growing prevents this
* cache from being reaped or shrunk.
* Note: The cache could be selected in for reaping in
* kmem_cache_reap(), but when the final test is made the
* growing value will be seen.
*/
/* Get mem for the objs. */
if (!(objp = kmem_getpages(cachep, flags)))
goto failed;
/* Get slab management. We talked about this func earlier, it just sets up slab_t structure
* and returns us a pointer to it. the struct may be in the slab or in a cache -in which case
* this fn. would have allocated an object for it via kmem_cache_create() */
if (!(slabp = kmem_cache_slabmgmt(cachep, objp, offset, local_flags)))
goto opps1;
/* Nasty!!!!!! I hope this is OK. well all the pages are contigous right?
* set the slab bit for each page. use each pages list pointers to point to
* the cache and slab so we can easily get them when freeing. here we see the
* macros that were shown above. */
i = 1 << cachep->gfporder; /* get total number of pages */
page = virt_to_page(objp); /* get the struct page for the base address */
/* pages will be laid out sequentially, so we go thru all of them and setup cache/slab pointers
* so that we can easily get them when freeing an object. also set the bit in the flags for the page
* that means this page is being used as part of a slab. */
do {
SET_PAGE_CACHE(page, cachep);
SET_PAGE_SLAB(page, slabp);
PageSetSlab(page);
page++;
} while (--i);
/* init this slabs objects. call constructors, and set up kmem_bufctl_t array */
kmem_cache_init_objs(cachep, slabp, ctor_flags);
/* clear growing flag, add the slab to free list -under lock protection */
spin_lock_irqsave(&cachep->spinlock, save_flags);
cachep->growing--;
/* Make slab active. add it to the free list, the failures value is not used elsewhere, for future?*/
list_add_tail(&slabp->list, &cachep->slabs_free);
STATS_INC_GROWN(cachep);
cachep->failures = 0;
spin_unlock_irqrestore(&cachep->spinlock, save_flags);
return 1;
opps1:
kmem_freepages(cachep, objp);
failed:
spin_lock_irqsave(&cachep->spinlock, save_flags);
cachep->growing--;
spin_unlock_irqrestore(&cachep->spinlock, save_flags);
return 0;
}
There are a couple of wrappers
around this next function that I won't show. The wrappers just lock
the caches spinlock to prevent concurrent access while it is being modified.
And they also return a meaningful value to the caller, depending on
which wrapper is called. View them yourself.
/*
* Called with the &cachep->spinlock held, leaves with it held
* this frees any slabs that are in the free list
* @param cachep - the cache to shrink
* @return - # slabs freed
*/
static int __kmem_cache_shrink_locked(kmem_cache_t *cachep)
{
slab_t *slabp;
int ret = 0;
/* all we do here is iterate through the caches free list and destroy all of the
* slabs that are on it.
* don't try to shrink if it is in midst of growing */
while (!cachep->growing) {
struct list_head *p;
/* if it is empty then stop here. when the prev/next pointers are pointing to the l
* ist head itself, that means that the list is empty */
p = cachep->slabs_free.prev;
if (p == &cachep->slabs_free)
break;
/* remove this slab from the list */
slabp = list_entry(cachep->slabs_free.prev, slab_t, list);
list_del(&slabp->list);
/* free its memory. we call conditional_schedule() so that if someone else was waiting for
* pages to be freed, they'll hopefully get a chance to run and grab what we just freed. note
* that we first need to drop the spinlock before sleeping in schedule()
*/
spin_unlock_irq(&cachep->spinlock);
kmem_slab_destroy(cachep, slabp);
conditional_schedule(); /* Can take 30 milliseconds */
ret++;
spin_lock_irq(&cachep->spinlock);
}
return ret;
}
Cache Reaping:
When the page allocator is
running low on free pages, it needs a way to reclaim as many pages as possible
can. One of the ways it does this is by 'cache reaping'. What
happens is that we try to find a cache with a significant number number
of pages on its free list, if we can find one, then we free all of these
pages. This action is performed by the kmem_cache_reap() function.
It traverses all of the caches by way of the cache_cache linked
list, looking for a cache that has at least 10 pages it can give back. If
it doesn't find one with 10 or more pages free, then it takes the best that
it could get. Once it has made its choice, it destroys half of the
free slabs. This function is not called in the cache management code,
it is called by do_try_to_free_pages() or __alloc_pages().
/**
* kmem_cache_reap - Reclaim memory from caches.
* @gfp_mask: the type of memory required.
* @return number of pages freed
*
* Called from do_try_to_free_pages() and __alloc_pages()
*/
int kmem_cache_reap (int gfp_mask)
{
slab_t *slabp;
kmem_cache_t *searchp;
kmem_cache_t *best_cachep;
unsigned int best_pages;
unsigned int best_len;
unsigned int scan;
int ret = 0;
/* we're traversing the cache_cache chain, we need to protect from concurrent access */
/* can we sleep or not? lock sem accordingly */
if (gfp_mask & __GFP_WAIT)
down(&cache_chain_sem);
else
if (down_trylock(&cache_chain_sem))
return 0;
/* these are used to maintain our search state */
scan = REAP_SCANLEN; /* traverse at most 10 caches*/
best_len = 0; /* saves the greatest number of free slabs */
best_pages = 0; /* saves the greatest numbef of free pages */
best_cachep = NULL; /* pointer to the cache with best stats */
searchp = clock_searchp; /* starts at cache_cache.next, each time this function is called it starts where it left off last time */
/* search thru at most 10 caches, trying to free slabs from them */
do {
unsigned int pages;
struct list_head* p;
unsigned int full_free;
/* It's safe to test this without holding the cache-lock. some caches can't be reaped from*/
if (searchp->flags & SLAB_NO_REAP)
goto next;
/* we don't try and free from a cache that is in the midst of growing in kmem_cache_grow() */
spin_lock_irq(&searchp->spinlock);
if (searchp->growing)
goto next_unlock;
/* if it has recently grown, clear the flag but dont reap from it. next time around it's fair game though */
if (searchp->dflags & DFLGS_GROWN) {
searchp->dflags &= ~DFLGS_GROWN;
goto next_unlock;
}
#ifdef CONFIG_SMP
{
cpucache_t *cc = cc_data(searchp);
if (cc && cc->avail) {
__free_block(searchp, cc_entry(cc), cc->avail);
cc->avail = 0;
}
}
#endif
/* ok got a cache, count how many free slabs it has by traversing free list */
full_free = 0;
p = searchp->slabs_free.next;
while (p != &searchp->slabs_free) {
slabp = list_entry(p, slab_t, list);
full_free++;
p = p->next;
}
/*
* Try to avoid slabs with constructors and/or
* more than one page per slab (as it can be difficult
* to get high orders from gfp()).
*/
pages = full_free * (1<<searchp->gfporder); /* pages = num slabs * pages per slab */
/* each of these tests scale down the # of pages by %20, or a minimum of 1 to make it less attractive.
*/
if (searchp->ctor)
pages = (pages*4+1)/5;
if (searchp->gfporder)
pages = (pages*4+1)/5;
/* update best variables. if we have enough pages (10), then this is our victim, else keep looping round */
if (pages > best_pages) {
best_cachep = searchp;
best_len = full_free;
best_pages = pages;
/* ok, this cache is our victim, get a pointer to it and break out of the loop */
if (pages >= REAP_PERFECT/* 10 */) {
clock_searchp = list_entry(searchp->next.next,
kmem_cache_t,next);
goto perfect;
}
}
next_unlock:
spin_unlock_irq(&searchp->spinlock);
next:
searchp = list_entry(searchp->next.next,kmem_cache_t,next);
} while (--scan && searchp != clock_searchp);
/* if we're here we didn't find a perfect match, but may have something */
clock_searchp = searchp;
if (!best_cachep)
/* couldn't find anything to reap */
goto out;
spin_lock_irq(&best_cachep->spinlock);
perfect: /* when we jump here we already have the spinlock locked */
/* free only 50% of the free slabs */
best_len = (best_len + 1)/2;
/* traverse free slab list, pull off slabs, and free them */
for (scan = 0; scan < best_len; scan++) {
struct list_head *p;
/* is someone trying to grow at same time?? */
if (best_cachep->growing)
break;
p = best_cachep->slabs_free.prev;
/* when we hit here the list is now empty */
if (p == &best_cachep->slabs_free)
break;
slabp = list_entry(p,slab_t,list);
list_del(&slabp->list);
STATS_INC_REAPED(best_cachep);
/* Safe to drop the lock. The slab is no longer linked to the
* cache. we call conditional_schedule() here so that whomever is waiting on the pages can grab them
*/
spin_unlock_irq(&best_cachep->spinlock);
kmem_slab_destroy(best_cachep, slabp);
conditional_schedule(); /* try_to_free_pages() */
spin_lock_irq(&best_cachep->spinlock);
}
/* unlock the cache, and return the total number of pages freed */
spin_unlock_irq(&best_cachep->spinlock);
ret = scan * (1 << best_cachep->gfporder);
out:
up(&cache_chain_sem);
return ret;
}
Kmalloc() and Kfree():
You're probably saying to yourself,
"wait a minute.. wasn't the topic of this article kmalloc()? so why haven't
we seen the code for it??". Well, yes, and I could show it here, but
it's absurdly simple now that you know the rest. So, you're encouraged
to go see it for yourself, all 10 lines of it.
Conclusions:
I set out to determine the
exploitability of kmalloc()'d buffer overflows, and in doing so
learned about how the kernel manages system RAM. Hopefully you too
have learned something, if you have more questions the source is the place
to go. In the future I might update this to include the SMP specific
code. I had avoided it, because well, I'm kind of lazy and I don't
even have an SMP machine. I was eager to figure out the answer to
my original question ASAP (took me a looong night), and after it was answered
I didn't really care about the SMP stuff to be honest. Perhaps if
it was a positive answer I would have been more motivated.
I am a bit suprised that the allocator was not something more complex. Having waded through Doug Lea's malloc code, with the help of some excellent Phrack articles -well I was prepared for some pretty confusing stuff here. Suprisingly, as you probably agree, it really isn't that complex at all. The kernel developers certainly made a smart decision by isolating the control blocks from the data blocks -at least moving them before the data that is. That situation makes exploiting kmalloc()'d buffers extremely tough. Perhaps one day the correct situation will arise though, and an underflow will occur that lets you overwrite large amounts of memory. I await that day eagerly :D
I am a bit suprised that the allocator was not something more complex. Having waded through Doug Lea's malloc code, with the help of some excellent Phrack articles -well I was prepared for some pretty confusing stuff here. Suprisingly, as you probably agree, it really isn't that complex at all. The kernel developers certainly made a smart decision by isolating the control blocks from the data blocks -at least moving them before the data that is. That situation makes exploiting kmalloc()'d buffers extremely tough. Perhaps one day the correct situation will arise though, and an underflow will occur that lets you overwrite large amounts of memory. I await that day eagerly :D